French Champagne Sales Forecasting
Overview
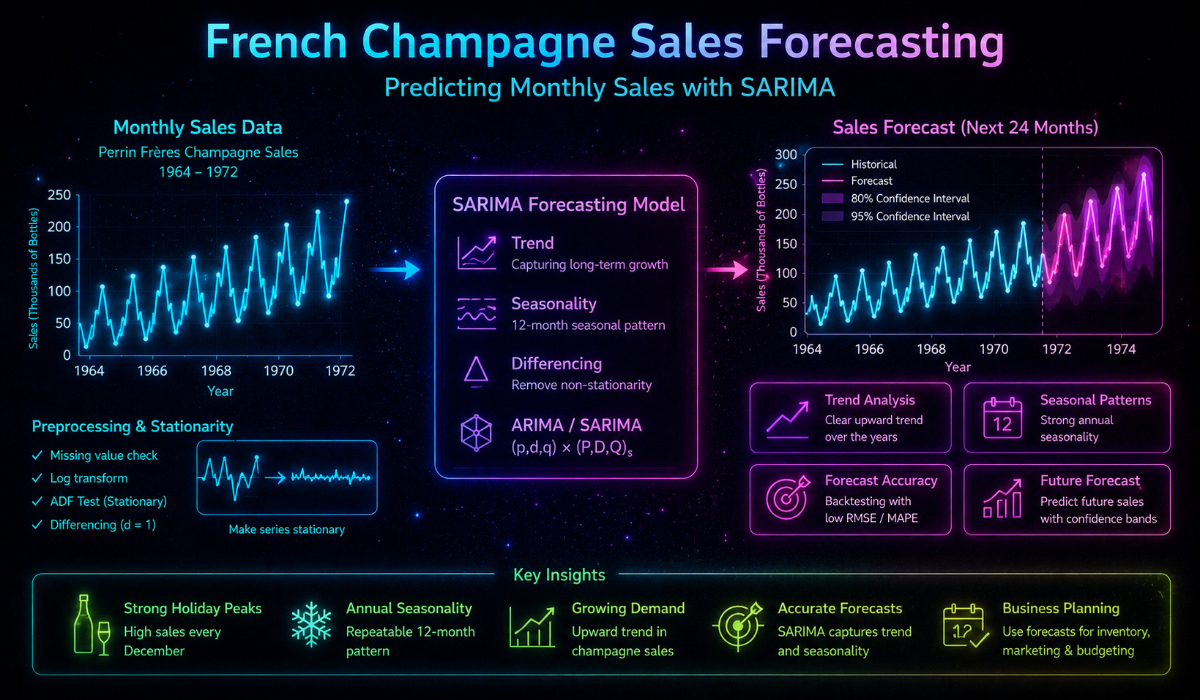
End-to-end time series forecasting study on monthly French champagne sales (Perrin Frères, January 1964 – September 1972). Three model families are developed and compared: ARIMA, SARIMA, and Holt-Winters exponential smoothing. Each follows a consistent four-stage pipeline — manual proof-of-concept, grid search, residual analysis, and bias-corrected held-out validation — so comparisons across model families are made on equal footing.
The project is structured across 15 notebooks, one per pipeline stage per model family, plus shared notebooks for data preparation, exploratory analysis, stationarity testing, and a naïve persistence baseline. The validation set is isolated before any modeling begins and used only for final evaluation.
Dataset
The series is sourced from Jason Brownlee's dataset repository: 105 monthly observations of Perrin Frères champagne sales from January 1964 through September 1972. The series exhibits strong seasonality with a pronounced December peak each year.
The held-out validation set — October 1971 through September 1972, one complete year, 12 observations — is split from the raw data before any modeling, analysis, or parameter selection. It is not examined during development. The training set contains 93 observations (January 1964 – September 1971). A seasonally differenced series (lag-12, 81 observations) is derived from the training set for stationarity analysis and ARIMA parameter selection.
Pipeline
Exploratory Data Analysis
The raw training series is examined for trend, seasonality, and variance behavior using a line plot, descriptive statistics, and annual box plots across 1964–1970. The box plots make the year-over-year seasonal pattern and variance structure visible before any modeling decisions are made.
Stationarity Analysis
The raw series is tested for stationarity using the Augmented Dickey-Fuller (ADF) test. Seasonal differencing at lag-12 is applied to remove the dominant seasonal component; stationarity is confirmed on the differenced series. ACF and PACF plots of the differenced series are used to inform initial ARIMA parameter selection. The differenced series is saved separately and used as input to the ARIMA pipeline.
Persistence Baseline
A naïve walk-forward baseline is established before any model development: the forecast at each step is the previous observed value. This sets a minimum performance threshold — any candidate model must demonstrate lower RMSE than the baseline to show genuine predictive skill. Baseline RMSE: 3186.501.
Models
ARIMA
The manual notebook fits ARIMA(1,1,1) on the manually pre-differenced series (lag-12 applied outside statsmodels) as a proof of concept, producing a training RMSE of 961.619. The grid search exhaustively evaluates all combinations of p ∈ [0, 6], d ∈ [0, 2], q ∈ [0, 6] on the raw training series.
A convergence guard is applied throughout the grid search. statsmodels raises a ConvergenceWarning rather than an exception when L-BFGS-B optimization fails, meaning non-converged fits pass silently through a bare except block. The mle_retvals['converged'] flag is checked explicitly after every fit; any non-converged configuration is excluded from evaluation. The best converged model is ARIMA(1,0,0) with a training RMSE of 945.107. Residual analysis is conducted on this configuration before applying bias correction. Final validation RMSE (bias-corrected): 390.870.
SARIMA
The manual notebook fits SARIMA(1,0,0)(1,1,0,12), passing the raw series directly to SARIMAX — unlike the ARIMA pipeline, no manual pre-differencing is required because SARIMAX handles seasonal integration internally via the D parameter. The grid search runs in two passes: a broad unrestricted search followed by a second pass with D fixed to 1, given the strong seasonal structure present in the data. Two candidate configurations are identified from the grid search and both are carried through residual analysis and bias-corrected validation. The best configuration is SARIMA(2,0,1)(1,1,0,12) with a training RMSE of 902.148. Final validation RMSE (bias-corrected): 722.929.
Holt-Winters Exponential Smoothing
The manual notebook fits a single configuration using statsmodels ExponentialSmoothing. The grid search evaluates all combinations of trend ∈ {add, mul}, damped ∈ {True, False}, and seasonal ∈ {add, mul}. Because ExponentialSmoothing does not expose an mle_retvals flag as ARIMA does, convergence is validated empirically by checking that all estimated smoothing parameters are finite and fall within [0, 1]. The best configuration is HW(trend=add, damped=False, seasonal=mul) with a training RMSE of 840.194. Final validation RMSE (bias-corrected): 358.853.
Results
All three models substantially outperform the naïve persistence baseline. Holt-Winters achieves the lowest validation RMSE and is the recommended model for this series.
| Model | Training RMSE | Validation RMSE |
|---|---|---|
| Persistence (baseline) | 3186.501 | — |
| ARIMA(1,0,0) | 945.107 | 390.870 |
| SARIMA(2,0,1)(1,1,0,12) | 902.148 | 722.929 |
| HW(trend=add, damped=False, seasonal=mul) | 840.194 | 358.853 |
The SARIMA model achieves the lowest training RMSE but generalises poorly relative to both ARIMA and Holt-Winters — its validation RMSE is nearly double that of the next worst model. Holt-Winters produces the best training and validation performance.
Development Environment
- Python 3.14.3
- pandas
- numpy
- matplotlib
- statsmodels
- scikit-learn
- Jupyter